CNN结构演化
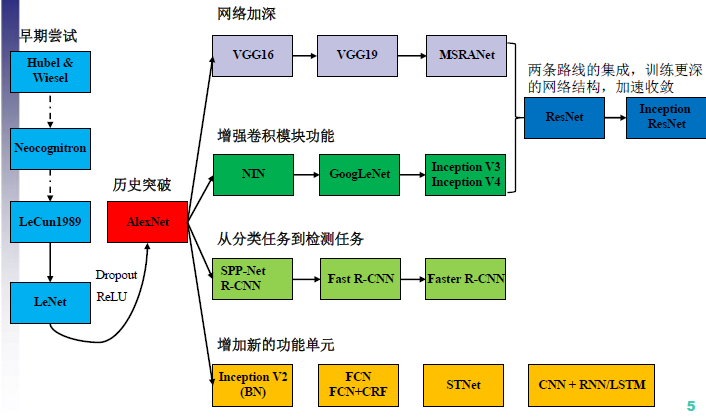
Inception 网络是 CNN 分类器发展史上一个重要的里程碑。在 Inception 出现之前,大部分流行 CNN 仅仅是把卷积层堆叠得越来越多,使网络越来越深,以此希望能够得到更好的性能。
例如第一个得到广泛关注的 AlexNet,它本质上就是扩展 LeNet 的深度,并应用一些 ReLU、Dropout 等技巧。AlexNet 有 5 个卷积层和 3 个最大池化层,它可分为上下两个完全相同的分支,这两个分支在第三个卷积层和全连接层上可以相互交换信息。与 Inception 同年提出的优秀网络还有 VGG-Net,它相比于 AlexNet 有更小的卷积核和更深的层级。
VGG-Net 的泛化性能非常好,常用于图像特征的抽取目标检测候选框生成等。VGG 最大的问题就在于参数数量,VGG-19 基本上是参数量最多的卷积网络架构。这一问题也是第一次提出 Inception 结构的 GoogLeNet 所重点关注的,它没有如同 VGG-Net 那样大量使用全连接网络,因此参数量非常小。
GoogLeNet 最大的特点就是使用了 Inception 模块,它的目的是设计一种具有优良局部拓扑结构的网络,即对输入图像并行地执行多个卷积运算或池化操作,并将所有输出结果拼接为一个非常深的特征图。因为 11、33 或 5*5 等不同的卷积运算与池化操作可以获得输入图像的不同信息,并行处理这些运算并结合所有结果将获得更好的图像表征。
迁移学习
什么是迁移学习
在深度学习中,所谓的迁移学习是将一个问题A上训练好的模型通过简单的调整使其适应一个新的问题B。在实际使用中,往往是完成问题A的训练出的模型有更完善的数据,而问题B的数据量偏小。而调整的过程根据现实情况决定,可以选择保留前几层卷积层的权重,以保留低级特征的提取;也可以保留全部的模型,只根据新的任务改变其fc层。
迁移学习能做什么
那么对于不同的任务,为什么不同的模型间可以做迁移呢?上面提到了,被迁移的模型往往是使用大量样本训练出来的,比如Google提供的Inception V3网络模型使用ImageNet数据集训练,而ImageNet中有120万标注图片,然后在实际应用中,很难收集到如此多的样本数据,也难以拥有足够的算力(Inception v3模型在一台配有 8 Tesla K40 GPUs,大概价值$30,000的野兽级计算机上训练了几个星期,因此不可能在一台普通的PC上训练,即使用实验室那台$10000的服务器也要跑几个月。我们将会下载预训练好的Inception模型,然后用它来做图像分类)。而且收集的过程需要消耗大量的人力物力,所以一般情况下来说,问题B的数据量是较少的。
所以,同样一个模型在使用大样本很好的解决了问题A,那么有理由相信该模型中训练处的权重参数能够能够很好的完成特征提取任务(最起码前几层是这样),所以既然已经有了这样一个模型,那就拿过来用吧。
所以迁移学习具有如下优势:
- 更短的训练时间
- 更快的收敛速度
- 更精准的权重参数。
但是一般情况下如果任务B的数据量是足够的,那么迁移来的模型效果会不如训练的好,但是此时起码可以将底层的权重参数作为初始值来重新训练。
利用inception-V3模型进行迁移学习
什么是Inception-V3模型
Inception-V3模型是谷歌在大型图像数据库ImageNet 上训练好了一个图像分类模型,这个模型可以对1000种类别的图片进行图像分类。但现成的Inception-V3无法对“花” 类别图片做进一步细分,因此本实验的花朵识别实验是在Inception-V3模型基础上采用迁移学习方式完成对“花” 类别图片进一步细分的实验。
Inception-V3模型一共有47层,详细解释并看懂每一层不现实,我们只要了解输入输出层和怎么在此基础上进行fine-tuning就好。
pb文件
要进行迁移学习,我们首先要将inception-V3模型恢复出来,那么就要到这里下载tensorflow_inception_graph.pb文件。
通常我们使用 TensorFlow时保存模型都使用 ckpt 格式的模型文件,使用类似的语句来保存模型
tf.train.Saver().save(sess,ckpt_file_path,max_to_keep=4,keep_checkpoint_every_n_hours=2)
使用如下语句来恢复所有变量信息
saver.restore(sess,tf.train.latest_checkpoint('./ckpt'))
但是这种方式有几个缺点,首先这种模型文件是依赖 TensorFlow 的,只能在其框架下使用;其次,在恢复模型之前还需要再定义一遍网络结构,然后才能把变量的值恢复到网络中。
谷歌推荐的保存模型的方式是保存模型为 PB 文件,它具有语言独立性,可独立运行,封闭的序列化格式,任何语言都可以解析它,它允许其他语言和深度学习框架读取、继续训练和迁移 TensorFlow 的模型。
它的主要使用场景是实现创建模型与使用模型的解耦, 使得前向推导 inference的代码统一。
另外的好处是保存为 PB 文件时候,模型的变量都会变成固定的,导致模型的大小会大大减小,适合在手机端运行。
bottleneck
bottleneck是我们经常用于描述网络最后一层之前的那些实际完成分类任务的网络层的一种非正式称谓。此倒数第二层已经过训练,可以输出一组足够好的值,以便分类器用来区分要求识别的所有类。这意味着它必须有足够丰富的信息,并且这些信息也足够紧凑,因为它必须包含足够的信息来在一小撮数值(标签值)中完成分类。重新训练最后一层就可以完成新的分类任务,因为在ImageNet数据上完成1000个分类任务的信息通常也可用于区分更细分的类别,比如inceptionV3已经可以区分哪些是花,哪些不是花是汽车、猫等,我们将不同种类的花喂给bottleneck层,输出的向量已经提取了足够的特征,用于帮助我们区分这是哪一个种类的花,我们只要在最后加一层全连接神经网络进行训练就可以了。
由于每张图像在训练和计算bottleneck值的过程中重复使用多次,这极为耗时,所以通常将这些数据缓存在磁盘上有助于加速整个过程以避免重复计算。
参考 https://zhuanlan.zhihu.com/p/30756181
参考 https://www.jianshu.com/p/3bbf0675cfce
参考 https://www.tensorflow.org/hub/tutorials/image_retraining